Divide and Conquer: Table Partitioning
Many projects go live with a data store, most using a relational database. At the start of a project, we may not know if and how successful an application might become or how it may grow beyond the original scope. Thus we may not pull out all the stops on optimising the database structure e.g. longevity.
One such thing that can happen in case your application continues to thrive is that some tables grow and grow and grow… At some point you may want to consider your options to keep these tables manageable.
One such option is to partition such a table. This means the table will be cut into pieces based on a property in the table, called the partition key. A property that does need to be chosen carefully, as it should help spread the data somewhat evenly over the partitions and should, ideally, be present in every query on that table.
The theory…
In principle, partitioning of a table means that we set up our table such that it looks like it is a single table, but in practice it consists of several smaller tables (see image 1). Each with a particular partition of the data. This could be data based on a particular property having a specific value or because it fits in a defined range of values. The former can i.e. be a string or number, the latter is typically a range of numbers or dates, but many databases also support hashes. It would be ideal if that property is also the primary key of the table, but that’s not always the case.
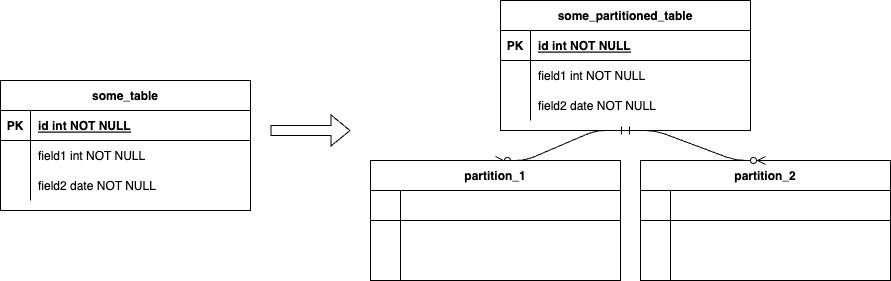
Image 1
So, when should we consider partitioning? A couple of reasons mentioned in the various database manuals include
- When a table reaches a certain size, e.g. Oracle mentions 2 GB
- When your table contains historical data and you add more data as time goes by; i.e. a billing system where you create new invoices over time
- When your data has different storage requirements based on its state; is it an active account or not, does it have to be searchable online or can it go into archival storage?
- If you want to improve performance… possibly
- Data retention, when your data can, or should, be removed after some time
…and the practice
All of the major databases support partitioning of tables in some form. All of them have their own limitations on how many partitions they support, what data types are available as partition keys, whether indexes work across all partitions, and whether they can then also guarantee unique constraints across the entire table or only per partition. To top it off, it can also differ per version of a particular database. So for more information on those nitty, gritty details I’ll refer to the individual database reference documentation. In this article I’ll use PostgreSQL to illustrate some examples.
Scenario 1: multi-tenancy
So let’s make this a bit more concrete and look at two scenarios. First an application where you store data for multiple customers in a way that can be described as multi-tenant. A single application with data for multiple users that should not be mixed up at all. Sure, we could start with a completely isolated application per tenant, but we all know that that may not be affordable when you start off, or even considered when it’s built for the first customer.
So we have a set of tables, each with a column tenant. That makes it an ideal candidate for the partition key.
Some of the benefits of partitioning the tables in this scenario are that you can isolate all the data for a particular tenant, maintenance on data for a particular tenant becomes possible without disturbing others, and, if needs be, it’s also easier to migrate a tenant to a separate instance if it grows too big to handle or has additional requirements due to changing rules and regulations like GDPR.
Scenario 2: historical data
Another example would be historical data. Many businesses will have some kind of billing or financial records system and they typically have to keep those records for a very long time due to tax rules. That does not mean you have to keep them easily available all the time though, and at some point you may also be able to move them to cheaper, archival storage or even throw them away.
The obvious benefit is of course that you can keep your active records set limited and thus keep performance in check, while not having to throw away or have more expensive data migration actions in place to get the same result. It also becomes easier to drop older data if it can finally be shredded. Just detach the partition, if you haven’t done so already, and then drop that single table instead of executing a series of delete statements followed by an autovacuum of the table to make up for the freed up space. The detach is trivial and almost instantaneous, the delete and subsequent re-index and vacuum are more complex and can be very taxing.
Implementing it in your database
If you have by now decided to go this route, what do you have to do to get here then? The easy approach would be to rename the old table, then create the new table and copy over all the data as is done in Listing 1.
ALTER TABLE invoices RENAME TO invoices_legacy;
CREATE TABLE invoices (
id BIGINT NOT NULL,
invoice_date DATE NOT NULL,
description VARCHAR(255) NOT NULL,
amount BIGINT NOT NULL,
discount BIGINT DEFAULT 0
) PARTITION BY RANGE (invoice_date);
-- use an arbitrary old date to fill the FROM date. TO is exclusive.
CREATE TABLE invoices_2023 PARTITION OF invoices
FOR VALUES FROM ('1900-01-01'::DATE) TO ('2024-01-01'::DATE);
CREATE TABLE invoices_2024 PARTITION OF invoices
FOR VALUES FROM ('2024-01-01'::DATE) TO ('2025-01-01'::DATE);
INSERT INTO invoices (id, invoice_date, description, amount, discount)
SELECT (id, invoice_date, description, amount, discount) FROM invoices_legacy;
Listing 1
This is not taking into account any indexes created previously for the old table, queries that do not take the invoice_date into account or views on the old table that may now point to the renamed table or other things your database of choice may or may not do due to a rename. Oh, and also not taking into account whether or not the choice of partition key here is actually the best possible… that I leave as an exercise for the reader 😉
Depending on the amount of data in the original table, this may also take quite some time to execute. In one case I was involved with, the original approach the developers took, the timer got to about a day for a dataset similar to production. Needless to say, at this point we asked a database administrator to help with optimising this. The resulting script still started with a rename, but didn’t have to copy over the old data. So instead of creating the new partition for the old data, we used a temporary constraint to prevent the database from checking all the data to see if it matches the range set on the partition. Listing 2 show how we could do this in our example:
-- ensure we do not check on the validity of the data, because we already know it's safe
ALTER TABLE invoices ADD CONSTRAINT invoices_y2023_c
CHECK(invoice_date >= '1900-01-01'::DATE AND invoice_date < '2024-01-01'::DATE) NOT VALID;
ALTER TABLE invoices ATTACH PARTITION invoices_legacy
FOR VALUES FROM ('1900-01-01'::DATE) TO ('2024-01-01'::DATE);
-- now that we have attached the data, we can remove the temporary constraint
ALTER TABLE invoices_legacy DROP CONSTRAINT invoices_y2023_c;
Listing 2
You may also want to check your database documentation as some also have (limited) support to partition an existing table in place, e.g. MySQL.
Now you have some idea how to implement it in your database. That does not mean you’re done with it yet. Depending on the type of partition key, you will have to put some procedures in place to create new partitions or risk a grinding halt of your application as it tries to insert data into something that isn’t there. Also detaching or even removing older partitions should be thought about. This could be automated but is not necessarily the best approach to take.
Implementing it in your application?
While table partitioning is primarily something in your database, it is not something you as an application developer can completely ignore. First and foremost, the choice of the partition key can be of effect on your queries to the database. If you do not take that into consideration, the database may have to query all partitions. That could lead to serious performance degradation.
Beyond that, you may be hit by some of the limitations of your database of choice when it comes to unique constraints (i.e. MySQL and Postgres have this) or the number of significant characters in names for tables, indexes and constraints (not too long ago limits of less than 64 characters were quite common, sometimes much less than that).
For those that use SQL queries directly, i.e. because you use JDBC or MyBatis, you’re on your own to go over all the queries in your application that use this table and rewrite your queries to use the partition key if and where necessary.
If you use JPA you may have a little less to do. Hibernate has added some basic support in version 6.2 which allows you to mark the @PartitionKey such that it will try to take that into account for at least update and delete statements (see Listing 3). Custom queries written in JPQL still require attention from a developer to optimise.
@Entity
public class Invoices {
@Id
private Long id;
@PartitionKey
private LocalDate invoiceDate;
…
}
Listing 3
EclipseLink also has a series of annotations for partitioning but those target database partitioning or clustering. Also interesting and it can benefit from table partitioning, but not directly useful here.
About that performance?
As one of the benefits, performance was mentioned but with a caveat. That is for a reason. Partitioning can indeed get you a nice performance boost, but only if your queries hit a single or a few partitions at most. Then it will only need to run over one or a few smaller indexes or smaller tables and that saves memory and going back-and-forth to the disk. So if you get a performance improvement heavily depends on whether you can get your queries to include the partition key and thus get the query planner to limit the amount of data you have to search through.
Summary
I hope you’ve gotten an idea on what you could do within your existing database when your tables grow beyond what you may initially have expected. Or maybe you already expect them to grow this large and you decide to start with this approach from the get go.
For some additional fun reading on an approach I have used on an existing set of tables, where we had constraints regarding existing data, possible downtime and some more, I leave you with this approach where we included the date in the id column of the table. It has its pros and cons and requires some customization in the code as well to make Hibernate aware of it, but it has been serving us for some time now.
This article was previously published in Java Magazine issue #2, 2024 by the NLJUG