Efficiently storing your domain model in Riak
![]() Domain modelling and persistence appear to be at odds with each other, no matter which persistence store you use. Over the years practices have been developed for storing a model in a relational database using ORM frameworks like Hibernate, and various design patterns to help mitigate a number of issues. Not all of these translate very well when using one of the NoSQL persistence stores however. In this blog I will describe a situation we recently came across when working with a model we have to store in Riak. I will detail the model, the typical relational solution in Riak and what alternatives you may want to consider to better work with the strengths and weaknesses of Riak.
Domain modelling and persistence appear to be at odds with each other, no matter which persistence store you use. Over the years practices have been developed for storing a model in a relational database using ORM frameworks like Hibernate, and various design patterns to help mitigate a number of issues. Not all of these translate very well when using one of the NoSQL persistence stores however. In this blog I will describe a situation we recently came across when working with a model we have to store in Riak. I will detail the model, the typical relational solution in Riak and what alternatives you may want to consider to better work with the strengths and weaknesses of Riak.
Why we chose Riak over a traditional RDBMS? That answer lies with various requirements including high volume usage patterns and multi data center support. Suffice to say we found the requirements were a better fit with Riak than any other system under consideration.
The domain model
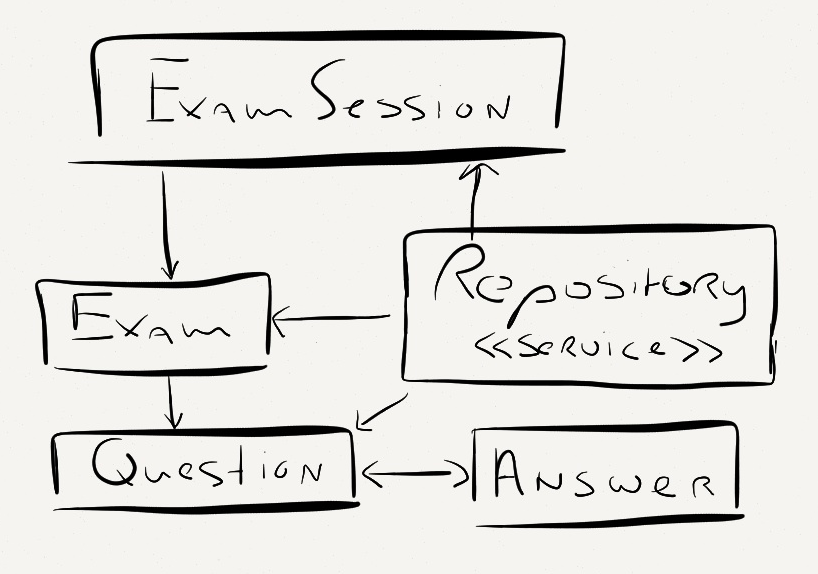
For every exam being taken an ExamSession instance will be created; a persistent session object. The Exam and Questions will typically be uploaded and not changed often, if at all. The ExamSession and Answers typically change a lot during the exam and afterwards should only be read.
Riak: the relational approach
So, what happens to our domain if we take the relational approach? We probably want to put every class in a bucket of its own, add some key field, and for concurrency issues a vClock field as well. Specific to the domain model we described above a more invasive change will be necessary: the relationship from the Questions to the Answers has to be severed and instead we will have a relationship from ExamSession to the Answers.
Relationships will be modelled with a key or a list of keys depending on the nature of the relationship. Bi-directional relationships will have to have those keys in both classes.

The Answers can be updated individually, when needed, as can the ExamSession.
Issues with the relational approach
Now, what happens if you have your ExamSessionRepository request a specific ExamSession? It will send a get to Riak for the ExamSession with a specific key. This will trigger Riak to send n requests to the replicas that should know how to retrieve the object for the given key. Not until at least r of those replicas have responded, will the original host in the cluster return.
On return, the application will have to retrieve the keys for the objects stored in other buckets, do a get for those as well until the entire object tree is complete. For an ExamSession this comes down to 1 ExamSession, 1 Exam, q Questions and a Answers being retrieved. For an exam with 30 questions with answers that amounts to 1 + 1 + 30 + 30 = 62 full round trips to Riak!
Some of this can be mitigated by using links and link walking in Riak, but even when using this technique the internal requests will still happen.
Even if the Exam and Questions are cached, and they probably should as they are practically constants compared to the life cycle of an ExamSession, we are still looking at 31 objects that need to be retrieved from Riak. For a system that can be described as ‘high throughput, high latency’, that is not an optimal solution.
Riak: an alternative approach
Reducing the number of round trips, whether full or partial, means we have to rethink the way we retrieve our data from Riak. Having a domain model we should be able to hide this from the domain itself through the use of the repositories.
A first step is to make a distinction between the data that has high and low update ratios. The Exam and Questions having a low update ratio means we can aggressively cache them. For the Questions we can also use lazy loading, as a candidate is only ever going to answer a single question at a time.
The ExamSession and Answers are updated quite frequently while a candidate is working on the exam. Answers are also closely related to the ExamSession so combining the two into a single object in Riak would reduce the number of requests to about one, for the cost of having a bigger payload per request. To achieve this merge, we identified three different approaches:
- Write a custom converter, based on the
Converterinterface of the Riak Java client - Write custom de-/serialisers using the appropriate Jackson interfaces and feed them to the
ObjectMapperin theJSONConverterused by the Riak Java client for conversion to and from JSON - Use DTO objects to de-/serialise the domain objects
Though the custom converter allows for a lot of flexibility in what and how to store in Riak, it also requires intimate knowledge of the domain, Riak as well as the Riak Java client API. We therefor discarded this option for our implementation.
A solution which requires less knowledge of Riak, almost none actually, was the de-/serialiser option. This requires you to create an implementation of the Deserializer and Serializer interfaces in Jackson for those classes you want to have custom persistence behaviour for and register them with the JSONConverter. Every time one of those classes is encountered during the de-/serialisation your custom implementation will be called. When I implemented this, I ran into some minor issues. The documentation for these interfaces is rather limited, so if you want to go beyond the “Hello World” scenario you are left to figure that out on your own. More serious I found the testability of the Serializer interface, or lack of testability actually.
In the end I implemented a DTO for the ExamSession that only contains the fields we want to persist. It required that the domain Repository became responsible for translating the domain object into a dto and vice verse. Though this introduces a construction into the domain for the sake of the persistence, we considered it the less invasive option. As a positive side effect, this means the @JsonIgnore and other hints for the JSONConverter in the actual domain object are no longer necessary.
A final change we made was to compress a particular string property in the Answer when storing it in Riak. This reduced the footprint of an Answer significantly (50+% reduction in size of an Answer was observed) and therefor of the entire ExamSession. Decompression can be done lazily so mitigating the added computational impact of this change.
Looking back at the number of round trips we mentioned in the previous section, we managed to bring this down even further. From the original 62 round trips in the example, we would now need just a single round trip for the entire ExamSession to be retrieved!
Summary
As discussed, the initial, perhaps naive, approach to use a relational strategy for storing your object model in Riak can have a serious impact on your performance and therefore your user experience.
However, taking a step back and combining the characteristics of Riak with the properties of your domain can lead to significant improvements. This may lead to changes in your domain model, but instead of changing your domain, you can also leverage your persistence service (a.k.a. Repository) to adapt your model to the persistence.
Read more about our QTI Assessment Delivery Engine stored in a Riak database for one of our customers or download a demo of the tool in action.