Handling a massive amount of product variations with Elasticsearch
In this blog we will review different techniques for modelling data structures in Elasticsearch. A project case is used to describe our approach on handling a small sized product data set with a large sized related product variations data set. Furthermore we will show how certain modelling decisions resulted in a 1000 factor query performance gain!
The flat world
Elasticsearch is a great product if you want to index and search through a large number of documents. Functionality like term and range queries, full-text search and aggregations on large data sets are very fast and powerful. But Elasticsearch prefers to treat the world as if it were flat. This means that an index is a flat collection of documents. Furthermore, when searching, a single document should contain all of the information that is required to decide whether it matches the search request.
In practice, however, domains often are not flat and contain a number of entities which are related to each other. These can be difficult to model in Elasticsearch in such a way that the following conditions are met:
- Multiple entities can be aggregated from a single query;
- Query performance is stable with low response times;
- Large numbers of documents can easily be mutated or removed.
The project case
This blog is based on a project case. In the project, two data sets were used. The data sets have the following characteristics:
- Products:
- Number of documents: ~ 75000;
- Document characteristics: A product contains a set of fields which contains the primary information of a product;
- Mutation frequency: Updates on product attributes can occur fairly often (e.g. every 15 minutes).
- Product variations:
- Number of documents: ~ 500 million;
- Document characteristics: A product variation consists of a set of additional attributes which contain extra information on top of the corresponding product. The number of product variations per product varies a lot, and can go up to 50000;
- Mutation frequency: During the day, there is a continuous stream of updates and new product variations.
An important aspect of these two data sets is that a product itself cannot be sold. A customer buys a product variation, which is based on a certain product.
The domain is depicted below:
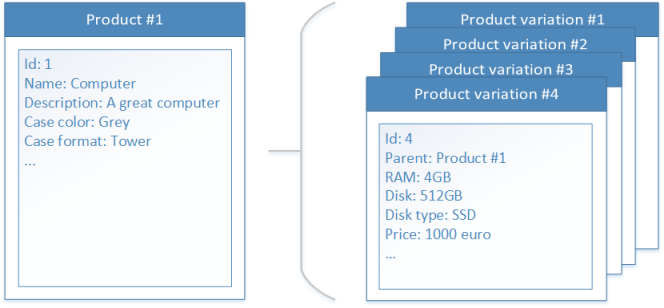
The existing implementation
When we were approached by the customer for this project, we first reviewed the existing implementation. This implementation was based on a parent/child relationship: the parent document (product) could have multiple child documents (product variations). In this way the “has_child” query in combination with the “children” bucket aggregation could be used to perform faceted search. Furthermore, it was easy to process updates/new product variations without the need to update the parent document (and vice versa).
Scalability concerns
The development and testing of the existing implementation was based on a small data set. A list of Elasticsearch queries was available to verify that the required information could be retrieved from the Elasticsearch index. However, there were some concerns whether the solution was able to scale up to the full production data set size: we noticed that the average response time increased during the product variations indexing process. To verify whether the concerns were legitimate, we set up a query performance test.
Query performance test
The query performance test is based on the following data sets:
- Products:
- Fixed size: 70,000 product documents.
- Product variation sample data sets with different orders of magnitude:
- Small: 100,000 product variation documents;
- Medium: 1,000,000 product variation documents;
- Large: 10,000,000 product variation documents;
- Extra large: 100,000,000 product variation documents.
The total set of available product variations contains around 500,000,000 items. Although the largest sample data sets only contains one fifth of the total set, it was sufficient to give us a feeling whether the approach was feasible for production.
The results immediately showed that this solution was not feasible:
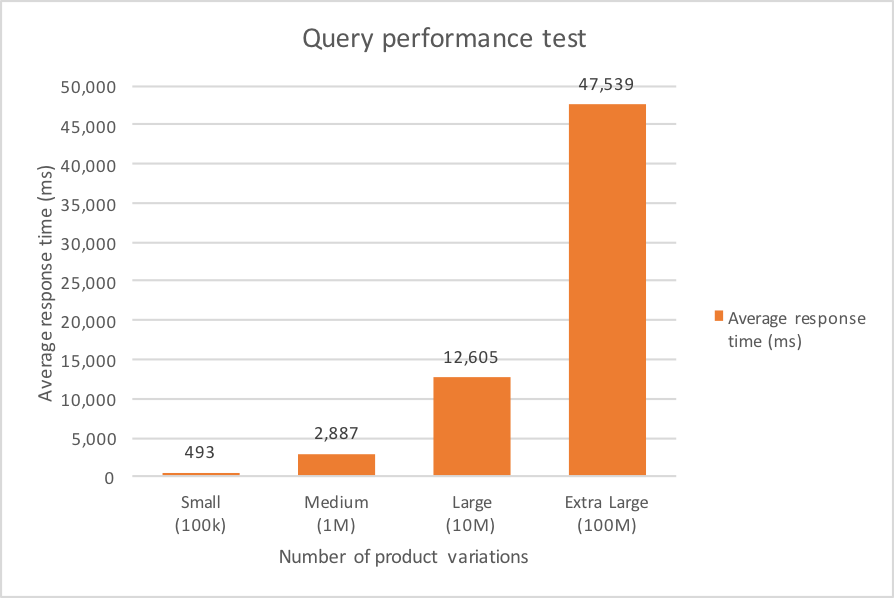
Although for the small data set the query performance was not that terrible, for larger data sets the average response times quickly became way too large. Furthermore, if we projected the average response time to the total set of 500,000,000 product variations, it became even more clear that this solution wasn’t the way to go.
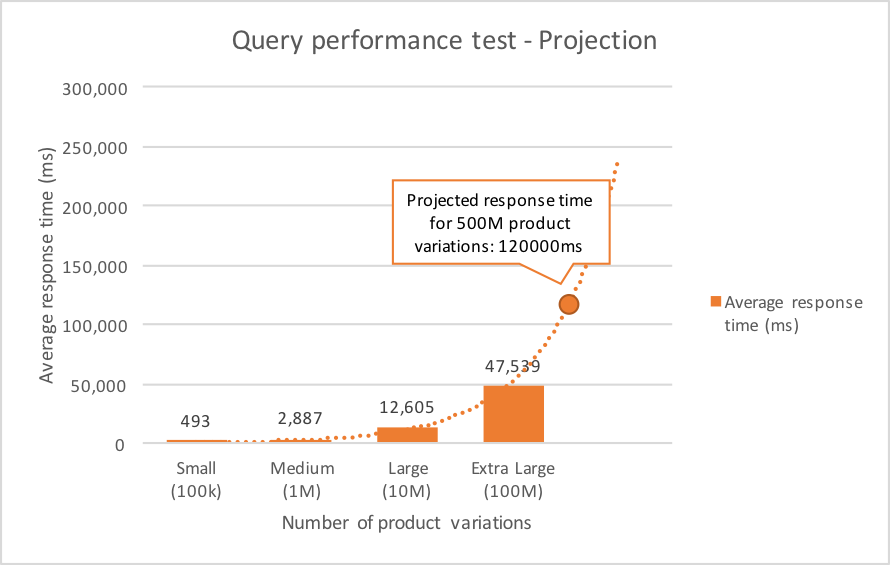
Query performance analysis
The Elasticsearch documentation states that when indexing child documents, you must specify the ID of the associated parent document. This ID is used to create a link between the parent and the child, and ensures that the child document is stored on the same shard as the parent.
In the domain of the project a small amount of parent documents (products) are related to a variable, possibly very large, amount of child documents (product variations). When all the child documents are indexed in the same shard as the parent document, it will be very hard to distribute the documents evenly over the available shards, and thus nodes in the cluster. We noticed that for the queries in our performance test we could not fully utilise the available resources in the cluster. Because of the way the parent and child documents are being stored and the relation between them is internally being maintained, the documentation states that parent-child queries can be 5 to 10 times slower than the equivalent nested query.
Time to come up with a new solution!
Functionality within the domain
Before you start modelling data structures in Elasticsearch it is important to understand which types of queries you have to answer. In this way, you get a better understanding of what fields need to be available in a document type, what sorting options will be used and what kind of aggregations will be performed.
In this case, the required query functionality can be broken down into the following types:
- Products can be retrieved based on auto suggest queries on product fields (e.g. product name, description, etc.);
- Results can be navigated through paging or dynamic loading;
- Results can be sorted on product attributes and product variation attributes;
- Results can be filtered on product attributes and product variation attributes;
- Detailed information of a product variation can be shown;
- From a product variation, filters can be changed or extended to find alternative product variations of the product.
The main challenges when implementing this functionality with respect to the characteristics of the data sets are performance related:
- How does querying on the large product variations data set affect the overall query performance?;
- How can we minimize the need to query the large product variations data set?
Reviewing the four techniques
The Elasticsearch documentation describes four common techniques for managing relational data:
- Application-side joins;
- Data denormalization;
- Nested objects;
- Parent/child relationships.
After the disappointing results of the parent-child implementation we reviewed the other three techniques to see if we could use some of those elements in our new implementation.
Application-side joins
Application-side joins can be used to emulate relations between different document types. The consuming applications can perform multiple search queries and combine the results. An advantage is that the data remains normalized. In our case this would be preferable, because changes in a product don’t imply changes in product variations (and vice versa).
Data denormalization
With data denormalization we add redundant copies of data into the index, in such a way that it removes the need for joins between relations. The advantage of this method is speed: documents contain all required information that is needed to determine whether it matches a search query.
In our case, the straightforward method of using data denormalization would be to add the product information fields to all product variation documents. The downside is that this would result in a very large increase in the size of the index. Furthermore, a change of a product property would imply a lot of updates of product variations.
Nested objects
By using nested objects, you keep the relation between multiple entities very close and store them in a single document. From an information point of view, it makes sense to store the product along with its possible product variations as a single document. It enables to query/filter on properties of both the product as the multiple related product variations. Because of the way the nested product variations are stored, joining them with a product at query time is very fast.
The downside of nested documents is that they cannot directly be accessed. They only can be accessed via the related root document. To add, update or remove a product variation, the whole product with all of its product variations need to be reindexed. In our case the product variations data set has a continuous stream of updates during the day. This would result in a continuous process of reindexing all data. Therefore, nested objects weren’t feasible for our project case.
In summary
Application-side joins:
- Pro: Data remains normalized.
- Cons: The consuming application needs to perform multiple search queries and combine the results.
Data denormalization:
- Pro: Good query performance, because a product variation contains all information of the related product.
- Con: A product update requires a lot of product variations updates.
Nested objects:
- Pro: Good query performance, because a product contains all of its product variations.
- Con: The continuous stream of product variations updates results in a continuous process of reindexing all data.
Our new solution
After reviewing the four techniques, we decided to take the following approach:
- Application-side joins: we can emulate the relation by first query on the products data set and then query on the product variations data set. However, we still need some mechanism to perform filters on both data sets in a single query;
- (Partially) data denormalization: we added filter fields to the product document type. The filter fields are essentially lists of possible filter values that were extracted of the set of product variations of each product. In this way we can perform filters on both data sets in a single query. Next to the the filter fields, we added a Lowest Price field. This field is used to sort the product data set in such a way that the product with the cheapest product variation gets on top of the search results.
The resulting document types are depicted below:
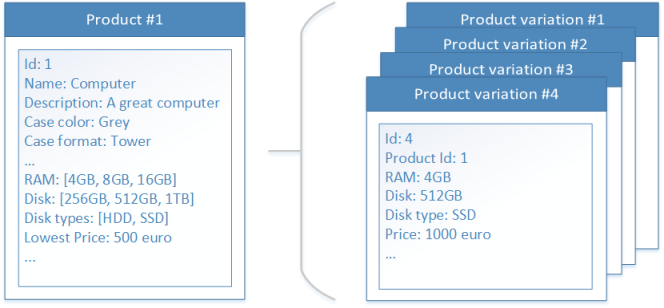
The approach described above directly gives us two benefits:
- By using this data denormalization method, the majority of the search queries can be performed against the small products data set;
- Explicit relations between document types are no longer needed. We can now use separate indices for each of the document types. This also gives us a lot of flexibility for our index settings (e.g. number of shards, number of replicas, analyzers).
Querying on the new indices
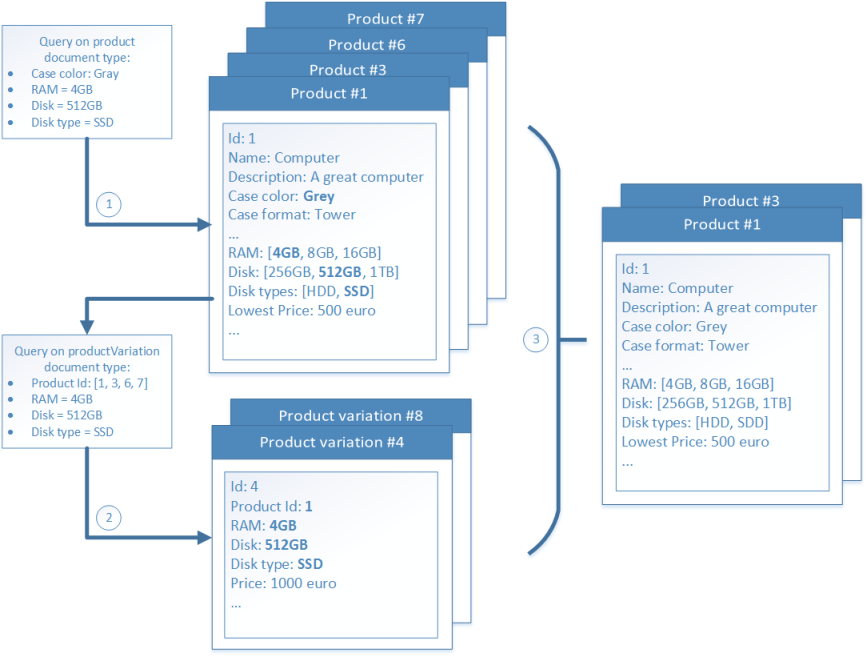
In order to test the new approach, we first needed to update our queries so that they can use the new indices. The most important change is related to the browse/filter mechanism. When you want to filter on a product field, no query change is necessary. When you want to filter on a product variation field, you now need to filter on the newly added filter list fields. When you want to filter on multiple product variation fields, querying on the filter list fields return a set of products for which a product variation exists that matches at least one (but not guaranteed all) filter value. Therefore, for this situation the query process is a little bit more complicated:
- First query on the product document type and use the filter list fields to retrieve the possible matching product variation documents;
- Next query on the product variations document type, filter on the list of possible matching IDs, and retrieve the product variations that match all of the given filter values; The result of this query is the list of matching product variation documents;
- From the result set of the first query, show only results if they have at least one matching product variation.
Note that by using this query proces, you need multiple queries to gather the requested results, which may result in an additional latency penalty. We will need to run the query performance test to see if this is a justified concern.
The described query process is depicted below:
The result
We updated the performance test with the new set of queries and ran the performance test again. It became clear that the resulting overall query performance was a lot better compared to the first approach. The results were as follows:
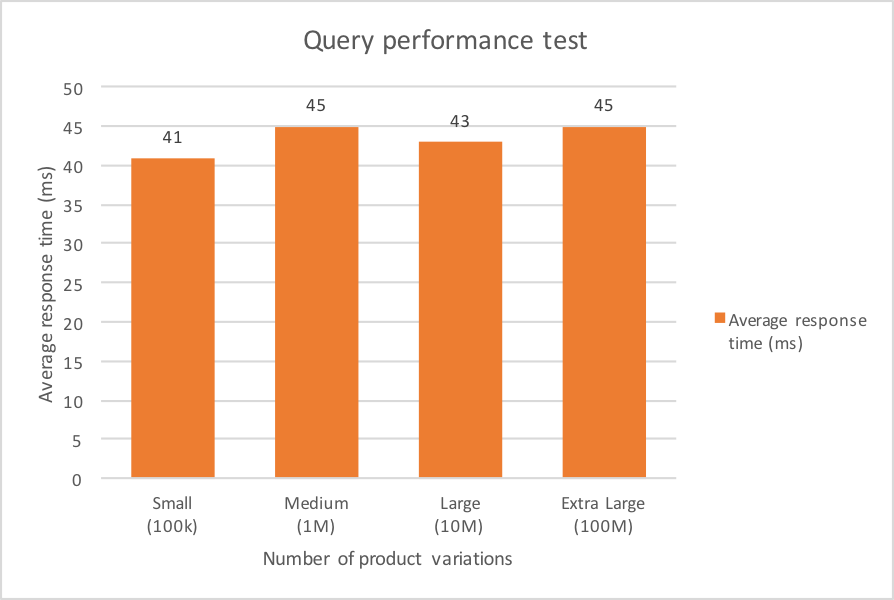
We see that the average response times over the different tests are really close to each other. The different results lie within the margin of deviation of a single test run. This can be confirmed by running the same performance test multiple times.
We can conclude that when the order of magnitude of the product variations set increases, the corresponding average query response time doesn’t significantly increase. This is a big win compared to the existing implementation! This difference can best be seen in the Extra Large data set test: the new solution is more than 1000 faster than the existing implementation.
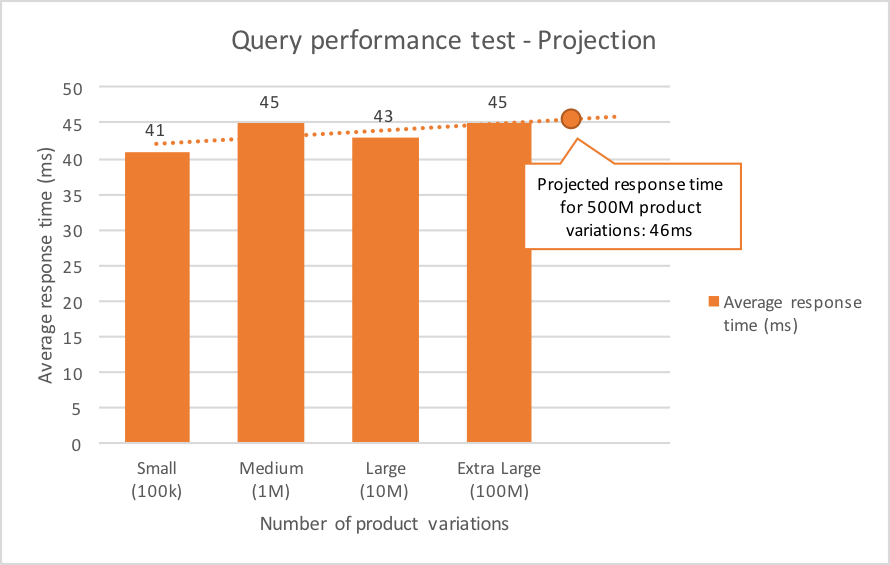
For sake of completeness we can give a projection of the trend line, but because the test results are so close to each other, this has no real added value.
Conclusion
Our solution in this project case resulted in a large query performance gain compared to the existing implementation. We reached this result because the solution was based on the following approach:
- Start from an end user point of view and gather functional requirements;
- Define which Elasticsearch query constructs needs to be used to enable this functionality;
- Design the data model in Elasticsearch with respect to the pros and cons of the different modelling techniques;
- Define a basic set of queries that shows that the data model contains all necessary information;
- Validate that the solution meets the non-function performance requirements by setting up a performance test based on these queries;
During this process, it can be very tricky to make the right modelling design decisions. The Elasticsearch documentation isn’t always clear on what is the best solution in different situations because it depends on so many variables. The best approach on tackling these kind of problems is set up a simple testing environment, set up a performance test that covers most of the required functionality and keep testing what the impact of changing the variables are. If you have set up this environment with some kind of automation, you can keep your changes small and iterate a lot and quickly have a better understanding of what is the best way to proceed in your solution.