How to avoid the split-brain problem in elasticsearch
 We’ve all been there – we started to plan for an elasticsearch cluster and one of the first questions that comes up is “How many nodes should the cluster have?”. As I’m sure you already know, the answer to that question depends on a lot of factors, like expected load, data size, hardware etc. In this blog post I’m not going to go into the detail of how to size your cluster, but instead will talk about something equally important – how to avoid the split-brain problem.
We’ve all been there – we started to plan for an elasticsearch cluster and one of the first questions that comes up is “How many nodes should the cluster have?”. As I’m sure you already know, the answer to that question depends on a lot of factors, like expected load, data size, hardware etc. In this blog post I’m not going to go into the detail of how to size your cluster, but instead will talk about something equally important – how to avoid the split-brain problem.
What is split-brain?
Let’s take as an example a simple situation of en elasticsearch cluster with two nodes. The cluster holds a single index with one shard and one replica. Node 1 was elected as master at cluster start-up and holds the primary shard (marked as 0P in the schema below), while Node 2 holds the replica shard (0R).
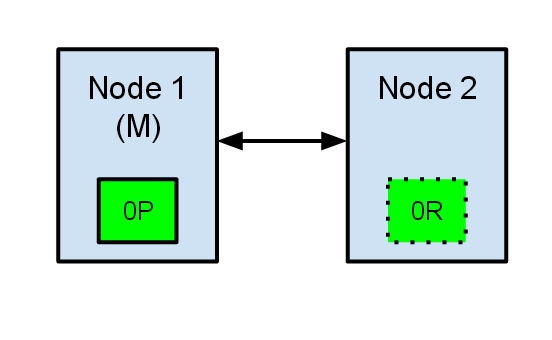
Now, what would happen if, for any reason, communication between the two nodes would fail? This could happen because of network failures or simply because one of the nodes becomes unresponsive (like in a case of a stop-the-world garbage collection).
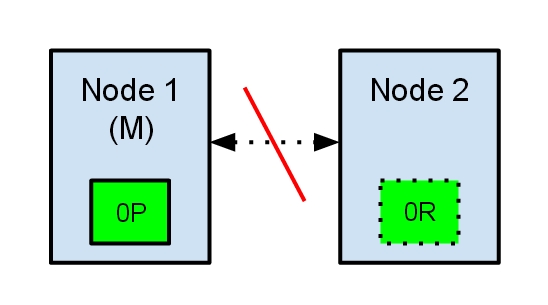
Both nodes believe that the other has failed. Node 1 will do nothing, because it’s already elected as master. But Node 2 will automatically elect itself as master, because it believes it’s part of a cluster which does not have a master anymore. In an elasticsearch cluster, it’s the responsability of the master node to allocate the shards equally among the nodes. Node 2 holds a replica shard, but it believes that the primary shard is no longer available. Because of this it will automatically promote the replica shard to a primary.
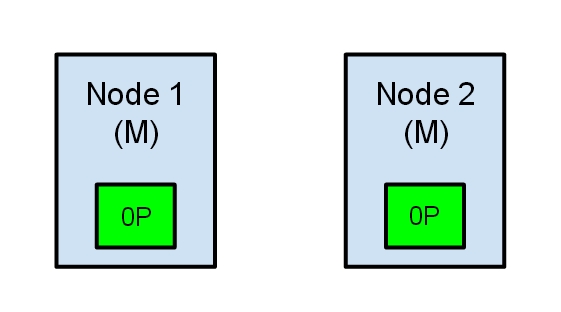
Our cluster is now in an inconsistent state. Indexing requests that will hit Node 1 will index data in its copy of the primary shard, while the requests that go to Node 2 will fill the second copy of the shard. In this situation the two copies of the shard have diverged and it would be really difficult (if not impossible) to realign them without a full reindexing. Even worse, for a non-cluster aware indexing client (e.g. one using the REST interface) this problem will be totally transparent – indexing requests will be successfully completed every time, regardless of which node is called. The problem would only be slightly noticeable when searching for data: depending on the node the search request hits, results will differ.
How to avoid the split-brain problem
The elasticsearch configuration has excellent defaults. However the elasticsearch team can’t know in advance all the details of your particular situation. That is why some configuration parameters should be changed to suit your specific needs. All the parameters mentioned in this post can be changed in the elasticsearch.yml file, found in the config folder of your elasticsearch installation.
For avoiding the split-brain situation, the first parameter we can look at is discovery.zen.minimum_master_nodes. This parameter determines how many nodes need to be in communication in order to elect a master. It’s default value is 1. The rule of thumb is that this should be set to N/2 + 1, where N is the number of nodes in the cluster. For example in the case of a 3 node cluster, the minimum_master_nodes should be set to 3/2 + 1 = 2 (rounding down to the nearest integer).
Let’s imagine what would have happened in the case described above if we would had set the discovery.zen.minimum_master_nodes to 2 (2/2 + 1). When the communication between the two nodes would have been lost, Node 1 would lose it’s master status while Node 2 would have never been elected as master. None of the nodes would accept indexing or search requests, making the problem immediately evident for all clients. Moreover none of the shards would be in an inconsistent state.
Another parameter you could tweak is the discovery.zen.ping.timeout. It’s default value is 3 seconds and it determines how much time a node will wait for a response from other nodes in the cluster before assuming that the node has failed. Slightly increasing the default value is definitely a good idea in the case of a slower network. This parameter not only caters for higher network latency, but also helps in the case of a node that is slower to respond because of it being overloaded.
Two node cluster?
If you think that it’s wrong (or at least unintuitive) to set the minimum_master_nodes parameter to 2 in the case of a two node cluster, you are probably right. In this case the moment a node fails, the whole cluster fails. Although this removes the possibility of the split-brain occurring, it also negates one of the great features of elasticsearch – the built in high-availability mechanism through the usage of replica shards.
If you’re just starting out with elasticsearch, the recommendation is to plan for a 3 node cluster. This way you can set the minimum_master_nodes to 2, limiting the chance of the split-brain problem, but still keeping the high availability advantage: if you configured replicas you can afford to lose a node but still keep the cluster up-and-running.
But what if you’re already running a two-node elasticsearch cluster? You could chose to live with the possibility of the split-brain while keeping the high availability, or chose to avoid the split brain but lose the high availability. To avoid the compromise, the best option in this case is to add a node to the cluster. This sounds very drastic, but it doesn’t have to be. For each elasticsearch node you can chose if that node will hold data or not by setting the node.data parameter. The default value is “true”, meaning that by default every elasticsearch node will also be a data node.
With a two-node cluster, you could add a new node to it for which the node.data parameter is set to “false”. This means that the node will never hold any shards, but it can be elected as master (default behavior). Because the new node is a data-less node, it can be started on less expensive hardware. Now you have a cluster of three nodes, can safely set the minimum_master_nodes to 2, avoiding the split-brain and still afford to lose a node without losing data.
In conclusion
The split-brain problem is apparently difficult to solve permanently. In elasticsearch’s issue tracker there is still an open issue about this, describing a corner case where even with a correct value of the minimum_master_nodes parameter the split-brain still occurred. The elasticsearch team is currently working on a better implementation of the master election algorithm, but if you are already running an elasticsearch cluster it’s important to be aware of this potential problem.
It’s also very important to identify it as soon as possible. An easy way to detect that something is wrong is to schedule a check for the response of the /_nodes endpoint for each node. This endpoint returns a short status report of all the nodes in the cluster. If two nodes are reporting a different composition of the cluster, it’s a telltale sign that a split-brain situation has occurred.
If you have concerns regarding your your current elasticsearch configuration or would like some help starting a new elasticsearch project, we are always ready to help, just contact us.
Update: if you’re curious how Java clients behave in a split-brain situation, take a look at this blog post.
