Improved search for Hippo CMS websites using ElasticSearch

 We have done multiple big Hippo projects. A regular Hippo project consists of multiple components like the website, the content management system and a repository for the documents. In most of the projects we also introduce the integration component. This component is used to pull other data sources into Hippo, but we also use it to expose data to third parties.
We have done multiple big Hippo projects. A regular Hippo project consists of multiple components like the website, the content management system and a repository for the documents. In most of the projects we also introduce the integration component. This component is used to pull other data sources into Hippo, but we also use it to expose data to third parties.
By default, the Hippo Site Toolkit delegates searches to the Hippo Repository that in turn delegates the search to Jackrabbit. This is the repository that is used by Hippo to store the documents. JackRabbit has integrated Lucene which can be used for search. This is a domain specific Lucene implementation targeting to be compatible with the Java Content Repository specification. This however comes at a price, for example more expensive and less customizable searches than search engines like Solr or Elasticsearch provides. for typical Solr/Elasticsearch features like highlighting, suggestions, boosting, full control over indexing or searching external content, Hippo Repository search is limited.
This search problem can be overcome using a specialized search solution like Elasticsearch. For multiple customers we have realized this solution, some based on Solr and others on Elasticsearch.
In this blogpost I am describing the solution we have created. I’ll discuss the requirements for creating (near) real time search using Hippo workflow events as well as the integration component that reads the documents from Hippo and pushes them to Elasticsearch.
Requirements for the solution
We are creating the possibility to search for content that can originate from Hippo but also from other sources. Elasticsearch must always contain all the content from Hippo. If we create a new document we want it to be available in Elasticsearch as soon as possible. If for some reason we are missing content we want to be able to import all content of a certain type or for a specific time interval. Therefore we need two different mechanisms to put content into Elasticsearch.
- Batch import – Makes use of queries for content types
- Event based import – Makes use of a queue in Hippo with (de)published documents
Obtaining the data
As I mentioned before we usually introduce an integration component in our hippo projects. I like to use spring integration to separate concerns of querying data and sending documents to Elasticsearch. We create different steps to query the repository for new content, to transform the incoming data to data we can send to other services, send the data to other services and to handle errors.
Sending data to Solr and Elasticsearch
Sending the data is straightforward. We use libraries like solr4j and elasticsearch java client. Of course you will need to define the structure of your document and map the Hippo beans to the beans that we send to the search engine.
One thing to remember is to think about committing documents. When using solr specifically it is better to set an auto commit after each minute or maybe 5 minutes depending on the amount of documents. If you do not want to do this you have to commit after each document you insert which is very heavy on solr and therefore slow in general.
(Near) real time search
Using Hippo workflow event
Hippo uses a workflow for publishing and de-publishing content. You can listen for these events on certain nodes. By listening to the events you can register which nodes have been published and which nodes have been de-published. I have created a very small plugin that registers two event listeners. By default these listeners listen for the changes in documents types: hippogogreen:newsitem. At the moment you have to change the plugin if you want to use it for your own project. I am planning on making this more generic in the future. I’ll show you what you need to change if you want to reuse this in your project. If you want more background information check the following links:
Hippo workflow events and Hippo xml import
You can find the sources at our github page:
https://github.com/triforkams/Hippo-Extensions (hippo-wf-event project)
I am not going into all the details for creating a plugin for Hippo. The basics steps are the following:
- Create a jar file with maven and include the data nucleus maven plugin for JDO enhancements to the workflow classes
- Create the workflow events, code will follow. Annotate the class with the right jdo annotations
- Add the persistence.xml for jdo configuration
- Create the hippo xml data files. I have two files, one for the configuration and another for the two folders that I need.
- Create the hippoecm-extension.xml that is picked up when starting the cms.
- Add the new jar to the dependencies of the Hippo go green cmd web application.
The package includes two events, one for published nodes and one for unpublished nodes. The following code block shows the important part for the published class.
@PersistenceCapable
public class SearchIndexUpdatePublishedDocumentEvent
extends AbstractWorkflowEvent
implements WorkflowEventWorkflow {
private static final Logger logger =
LoggerFactory.getLogger(
SearchIndexUpdatePublishedDocumentEvent.class);
private static final long serialVersionUID = 1L;
@Persistent(column = "jcr:uuid")
private String jcrUuid;
private SearchIndexUpdateHelper helper;
public SearchIndexUpdatePublishedDocumentEvent()
throws RemoteException {
super();
helper = new SearchIndexUpdateHelper(this);
}
@Override
public void fire()
throws WorkflowException, MappingException,
RepositoryException, RemoteException {
logger.debug("{} fired: jcrUuid={}",
this.getClass().getName(), jcrUuid);
try {
Long scheduledDate = helper.getScheduledDate(
getDocumentNode());
long currentTime = System.currentTimeMillis();
if (scheduledDate <= currentTime) {
helper.publishedDocument();
}
} catch (RepositoryException e) {
logger.error("RepositoryException by uuid {} on firing event", jcrUuid, e);
}
}
@Override
protected String getJcrUuid() {
return jcrUuid;
}
}
The helper class takes care of most of the work. This is easier when doing development since this class does not need to be enhanced by JDO. The event does check if the document is published in the future. You have to be careful, because the document will again pass this code when it is actually published. Therefore we do nothing when the publication is a request for the future. The next code block shows one of the methods that receives an updated node. It first checks if there is already an update in the queue, if not it will create a new document and stores it in the queue. After that it also checks if a delete/unpublish request was also in the queue. If so, that will be removed.
public void publishedDocument() throws RepositoryException {
Node documentNode = getDocumentNode();
String nodeType = documentNode.getPrimaryNodeType().getName();
if (!indexedTypes.contains(nodeType)) {
logger.info("We are not interested in objects of type : {}", nodeType);
return;
}
String handleIdentifier =
documentNode.getParent().getIdentifier();
Long scheduled = getScheduledDate(documentNode);
Session jcrSession = getJcrSession();
// Search published nodes
Node publishedNodes =
jcrSession.getNode(SEARCH_PUBLISHED_PATH);
Node publishedNode;
if (publishedNodes.hasNode(handleIdentifier)) {
publishedNode =
publishedNodes.getNode(handleIdentifier);
} else {
publishedNode =
publishedNodes.addNode(handleIdentifier);
}
publishedNode.setProperty(PUBLISHED_DOCUMENT_PROPERTY,
documentNode.getIdentifier());
publishedNode.setProperty(SCHEDULED_DATE, scheduled);
// Remove previous unpublished nodes if available
Node unpublishedNodes =
jcrSession.getNode(SEARCH_UNPUBLISHED_PATH);
if (unpublishedNodes.hasNode(handleIdentifier)) {
jcrSession.removeItem(SEARCH_UNPUBLISHED_PATH +
"/" + handleIdentifier);
}
jcrSession.save();
}
In the first few lines we check if we want to index the documents of the type of the current document. This is different than the check that is done by Hippo. When registering the workflow event we also have to provide a type of the document we are interested in. Usually we specify the parent document type in here
- hippogogreen:document
. Within the shown helper class we check if the current type is part of the indexedTypes collection. In our case we have specified only 1 type
- hippogogreen:newsitem
. At the moment you cannot configure this, but we will change this in the future.
The result of this plugin is an entry in one of the two folders as configured in the file
- data.xml
. The following image shows the nodes in the hippo console. The Integration is picking up the nodes in this Queue (which is actually just a node). This part is described in the following section.
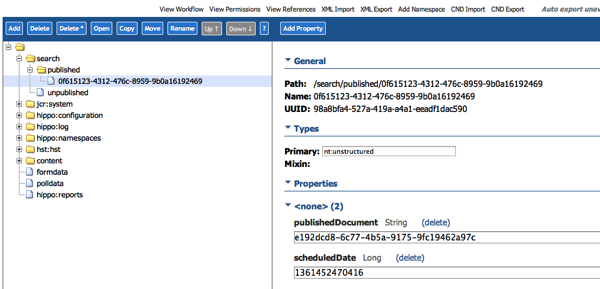
Reading the (de)publications from Hippo
Using very basic code we can read the node identifiers from the hippo repository. After reading the nodes and handling them, we remove the node from the repository.
Providing the search
In the end we create a search box in an hst site. This box is handled by our own controller and sends the query to elastic search or solr. The results are mapped back into Hippo site beans. That way we can reuse pagination functionality and more important we can use the hst to resolve the right links to the actual documents. We do not store these links because they can change. We just store the id of the document and let the hst help us resolving the current urls for the documents.
Last thoughts
At the moment we use workflow events to get the content. In a more recent version of hippo another mechanism is available. It should not be to hard to rewrite it, but for the older (7.7 and down) this works.
You can find the source for the workflow events handling at our github repository.
https://github.com/triforkams/Hippo-Extensions
If you have any specific questions with regards to Hippo, Search or a combination of the two please just drop us a note and we’ll be glad to help.