Maximum shard size in elasticsearch
 Whenever people start working with elasticsearch they have to make important configuration decisions. Most of the decisions can be altered along the line (refresh interval, number of replicas), but one stands out as permanent – number of shards. When you create an index in elasticsearch, you specify how many shards that index will have and you cannot change this setting without reindexing all the data from scratch. In some cases reindexing is not a time consuming task, but there are situations where it can take days to rebuild an elasticsearch index.
Whenever people start working with elasticsearch they have to make important configuration decisions. Most of the decisions can be altered along the line (refresh interval, number of replicas), but one stands out as permanent – number of shards. When you create an index in elasticsearch, you specify how many shards that index will have and you cannot change this setting without reindexing all the data from scratch. In some cases reindexing is not a time consuming task, but there are situations where it can take days to rebuild an elasticsearch index.
Many developers feel the pressure of making the right choice in regards to the number of shards they will use when creating an index. But with a base line of what the maximum shard size is and knowing how much data needs to be stored in elasticsearch, the choice of number of shards becomes much easier.
When I started working with elasticsearch a while ago, I was fortunate enough to work alongside a very talented engineer, a true search expert. I would often ask him questions like “So how many shards can one elasticsearch node support?” or “What should the refresh interval be?”. He would pause, think for a while, but in the end his answer would always be “Well, it depends”. This answer irked me in the beginning, especially because we’re in IT, where everything is 0s and 1s, right? In this blog post I will show what the answer to the question “How much data can a single-shard index hold?” depends on and how to find the best setting for your environment.
Test setup
For testing the limit of a single shard, I chose to index all the English Wikipedia articles, as they were on 8th of August 2013, without any version history. Wikipidia states that the number of English articles is over 4 million, so this should give us a nice platform to test on. Even without the revision history information, the unpacked Wikipidia dump file is around 42GB in size.
An article in the Wikipedia dump has a very simple XML format:
<br>
<page><br>
<title>AfghanistanHistory</title><br>
<ns>0</ns><br>
<id>13</id><br>
<redirect title="History of Afghanistan" /><br>
<revision><br>
<id>74466652</id><br>
<parentid>15898948</parentid><br>
<timestamp>2006-09-08T04:15:52Z</timestamp><br>
<contributor><br>
<username>Rory096</username><br>
<id>750223</id><br>
</contributor><br>
<comment>cat rd</comment><br>
<text xml:space="preserve"><br>
#REDIRECT [[History of Afghanistan]] {{R from CamelCase}}<br>
</text><br>
<sha1>d4tdz2eojqzamnuockahzcbrgd1t9oi</sha1><br>
<model>wikitext</model><br>
<format>text/x-wiki</format><br>
</revision><br>
</page><br>
The above example is a redirect page. In this case the text element does not hold much information. If the redirect tag is not present then the text element will hold the actual full text of the article. The following fields from the XML will be indexed in elasticsearch: title (both analyzed and not analyzed), id, redirect (true/false flag), timestamp, username (not analyzed), comment (analyzed & stored) and text (analyzed & stored). Storing the text field may seem a strange choice. Indeed, if I were building a real-life application and the text would already be present in a database, I would never store it in elasticsearch, I would only analyze it. But this is a test to find the limits of a single shard in elasticsearch – the more data, the better.
The test was done on my development laptop. The full test specifications are:
- i7-3630QM CPU (2.40GHz, 4 core, HT)
- 16GB RAM
- Windows 8 64b
- OS on SSD, elasticsearch on HDD
- Oracle Java 1.7.0_25
- elasticsearch 0.90.5 (latest at the time of writing)
- 6GB of memory allocated to elasticsearch (rest of JVM options left at default)
- 1 shard, 0 replicas
- refresh interval: 5s
Indexing data
I quickly wrote a small Java application that streams the XML Wikipedia dump, assembles an object containing the fields mentioned above and sends it to elasticsearch for indexing. Index requests were bulked up in 1000 documents at a time. Below you can see a graph of the time it took to index each bulk of 1000 documents (time is in milliseconds). In total, a little over 6 hours were spent indexing the full Wikipedia dump.
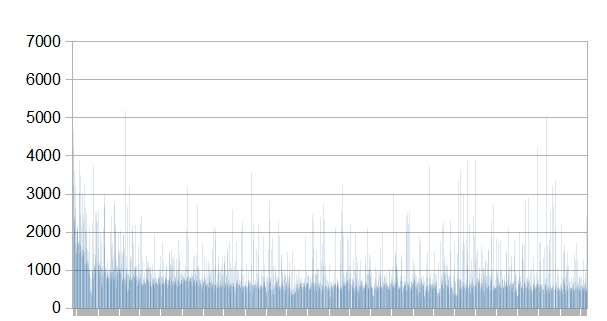
To be perfectly honest, I was surprised with the result. I expected either the elasticsearch process to run out of memory, or indexing to become really slow towards the end of the data set. It can be seen from the above graph that the indexing actually got a little faster as time went on. Regarding memory, below is a screenshot from JConsole showing the memory usage during the indexing process.
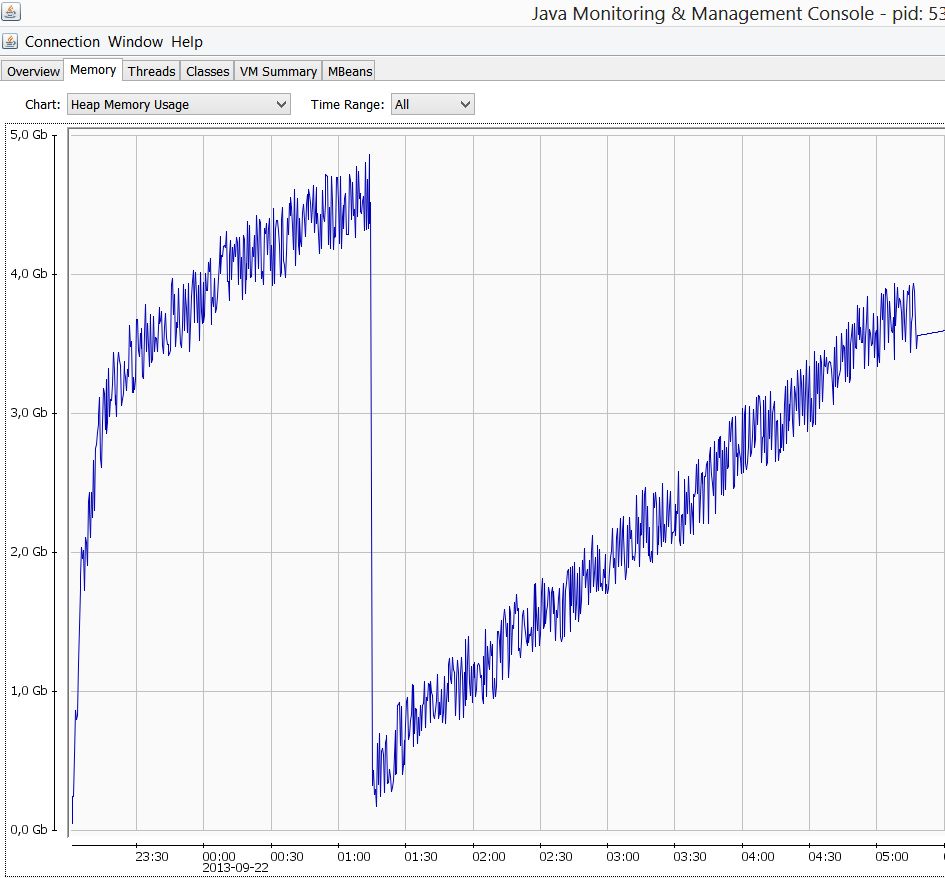
As you can see, it was nowhere close to an out of memory exception. At the end of the indexing process, a single stop-the-world garbage collection had been done (for a whopping 50ms) and about a minute’s worth of ParNew garbage collections. If you are curious, elasticsearch’s data folder stands at 41.4 GB, around half a gigabyte less than the full XML dump – a testament on how efficient Lucene actually is at storing data. True, I haven’t indexed all the fields in the XML, but still, it’s impressive.
The takeaway from the indexing test is that elasticsearch can comfortably index a lot of data in a single shard. The results will vary depending on your data structure and server size, but the full English Wikipedia proved to be no problem for a single shard from an indexing performance point of view.
Querying the full index
But indexing is only half the story. Nobody will index 40GB of data just for the fun of it, we also want to search it. This is a simple query I did against the elasticsearch Wikipedia index:
<br>
{<br>
"query": {<br>
"filtered": {<br>
"query": {<br>
"match": {<br>
"text": "top gear"<br>
}<br>
},<br>
"filter": {<br>
"term": {<br>
"redirect": "false"<br>
}<br>
}<br>
}<br>
},<br>
"facets": {<br>
"user": {<br>
"terms": {<br>
"field": "contributorName",<br>
"size": 25<br>
}<br>
}<br>
}<br>
}<br>
It took ~200ms to return the results. But a single user with a single query doesn’t represent much load to the system. The next logical step is to write a JMeter test, to simulate the load that a number concurrent users would put on the system. I chose to do the test with 500 concurrent users. While this may not seem like a large number, it’s probably more than what the average system will have to support during its lifetime. The same query as above was executed, but the query text was chosen at random out of the list of countries and a list of US cities. The summary results are shown in the table below.
| Samples | Average response time (s) | Minimum response time (s) | Maximum response time (s) | Error % |
| 25000 | 28.5 | 0.13 | 103 | 0.01% |
Ignoring the 0.01% failures (encoding issues in the query text, nothing to do with elasticsearch), an almost 30 second average response (with a maximum higher than one and a half minutes) is not acceptable for any system in this day and age. Also, the CPU usage during the test can be seen below:
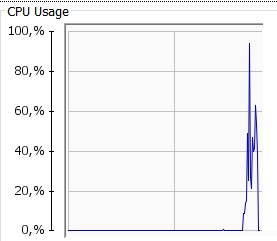
Spikes to more than 95% don’t look good – it’s obvious that the machine was as close to its limits as you would want in a production environment.
Wrapping up
When I started writing this blog I honestly expected to find a definite answer to the question “What is the maximum shard size in elasticsearch”, but the truth is it depends. It depends on your particular data structure and indexing & querying requirements. For example, in my Wikipedia test, the indexing performance was acceptable, but the querying with 500 concurrent users was not. But how many systems have to support 500 concurrent users? Elasticsearch is used for reporting where only a couple of users at a time actually query the system. On the other hand, it’s used in real time scenarios, where indexing and querying (possibly both from multiple threads) are done at the same time. Unfortunately there is no magic formula to find an answer to the question “How much data can a single shard hold?”. To find the correct answer for your situation, you are going to have to test elasticsearch in a similar way I did here.
Something to remember is that the Wikipedia test is empirical – querying and indexing were done independently from each other, and I only indexed documents in an empty index. Most of the times, in a real-life scenario, documents would get updated, deleted, reindexed without ever starting from scratch and querying would be done at the same time as indexing. Because of this, you should do a capacity management test that reflects as close as possible the manner in which elasticsearch will be actually used. Ideally, I would test with production data, trying to replicate as closely as possible the expected load of indexing and querying. A proper test would also go over the expected limits, to get a better understanding of how much leeway in supporting more data and users the system has.
In my next blog in the “it-depends” series, I will expand on the Wikipedia test, trying to show how different configuration decisions can affect the performance of the cluster.
If you want to know more on how to plan for a new elasticsearch implementation, or how to improve your existing cluster’s performance, don’t hesitate to contact us.
