Migrating Verity to Elasticsearch at Beeld & Geluid
![]() Nederlands Instituut voor Beeld & Geluid: Beeld & Geluid is not only the very interesting museum of media and television located in the colorful building next to the Hilversum Noord train station, but is also responsible for the archiving of all the audio-visual content of all the Dutch radio and television broadcasters. Around 800.000 hours of material is available in the Beeld & Geluid archives – and this grows every day as new programs are being broadcasted.
Nederlands Instituut voor Beeld & Geluid: Beeld & Geluid is not only the very interesting museum of media and television located in the colorful building next to the Hilversum Noord train station, but is also responsible for the archiving of all the audio-visual content of all the Dutch radio and television broadcasters. Around 800.000 hours of material is available in the Beeld & Geluid archives – and this grows every day as new programs are being broadcasted.
This blog entry describes the project Trifork Amsterdam is currently doing at Beeld & Geluid, replacing the current Verity search solution with one that is based on Elasticsearch.
 The full archive of Beeld & Geluid is available to the general public. Users can search for and purchase full or partial broadcasts of their favorite shows. Next to this, broadcasters have their own dedicated website for searching the same archive. Broadcasters use this website, for example, to search for footage of Queen Beatrix from 10 years ago. They can purchase the rights to the footage and include it in the evening news.
The full archive of Beeld & Geluid is available to the general public. Users can search for and purchase full or partial broadcasts of their favorite shows. Next to this, broadcasters have their own dedicated website for searching the same archive. Broadcasters use this website, for example, to search for footage of Queen Beatrix from 10 years ago. They can purchase the rights to the footage and include it in the evening news.
Goal of the project
Trifork is currently working on the project to replace the existing search solution of the content archive. Although still reasonably fast and usable, Beeld & Geluid has made the decision of replacing the current search solution with a more modern full text search engine. The decision took into consideration two factors. Firstly, the existing engine is proprietary and has reached end-of-life, support no longer being offered. Secondly, Beeld & Geluid would like to open its searchable archive to other input sources, but also to other search interfaces. This will be easier to accomplish with a system designed to be open from the start.
Our main goal for the first phase of the project is to replace the current full text search system, while keeping the changes oblivious to both the input and the output interfaces. In short, if in a couple of months from now you will happen to visit the Beeld & Geluid online catalogue and will see no change in the behavior of the search (other than being a little faster), it means that we did our job properly.
Short overview of the online catalogue searching solution
In the Beeld & Geluid online catalogue, we consider a document to contain all the information regarding a particular broadcast: title, description, summary, date of broadcast etc. Currently there are two types of documents that are searchable in the catalogue: one containing the full broadcast and another containing just a selection of it (e.g. if talking about a broadcast of a football match, a selection could be the first half of the match).
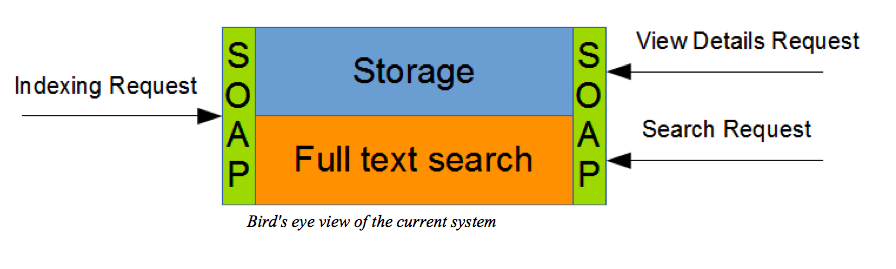
Internally, documents are stored as XMLs (“Storage” area of the above drawing). The XML is also parsed and relevant data is sent to the full text search engine for indexing.
The system receives indexing requests of a new broadcast in the form of SOAP requests. From the searching interfaces (searching websites) the system also receives SOAP requests. There are two major types of searches: search requests – these are internally handled by the full text search engine – and view document details requests – internally handled by the storage. As the name says, a view document detail request is done when the user clicks to view the details of the document. This happens after the user has performed a search – at this point the id of the document is known, making it simple to be retrieved from a storage system.
Replacing the full text search engine
It comes as no surprise that we chose Elasticsearch to replace the full text search engine. We chose it over Solr for what we feel is an easier to use Java API and for the clustering and fail-over support that Elasticsearch provides out-of-the-box.
Replacing the storage backend
A NoSQL database is an ideal candidate for replacing the current storage solution. There is very little dependency between the documents, each document must be stored and returned as XML and most of the requests are done by id. We considered MongoDB, but in the end decided to use Elasticsearch as storage as well. This helps us keep the application stack small, that in turn speeds up the learning curve for new developers. The requirements for the storage are not extraordinary – as previously said we basically only need to store an XML and retrieve it by a document id. Elasticsearch, although maybe not as powerful as dedicated NoSQL databases has proved sufficient for our needs. Also, the before-mentioned clustering and fail-over support are a big plus.
What we have achieved so far & what still needs to be done
We are not done yet, but we did make a good start. So far we successfully implemented both SOAP web services, have a fully functioning Elasticsearch storage backend and have done plenty of work on replacing the full text search engine with Elasticsearch. We recently demoed a full end to end working solution, where we indexed several hundred documents, performed a search (getting back the relevant results) and also showed the document details.
In addition to sharing our technical expertise, Trifork has also introduced Beeld & Geluid to the Scrum development framework. We helped with the planning and estimation meetings, facilitated the retrospectives, and generally answered any questions our customer might have had about the process. The described work has been accomplished in two sprints of 3 weeks each.
In the following two sprints we plan to wrap everything up with the Elasticsearch index – there is still work to be done there for facets, sorting, results highlighting and implementing all the different queries that the current solution supports.
This is just a brief insight into the project is you want to know more just contact us and in time we will also do a sequel blog post to this one too.