Persist beans to the Magnolia repository with the OM module

Every once in a while when developing some integration with Magnolia CMS, you might want to save the contents of a bean to a Magnolia node. The other way around, from content node to a bean, has never been an issue due to the Content2Bean utilities that Magnolia provides. You might have already stumbled upon the Bean2ContentProcessor and the Bean2ContentTransformer interfaces in the Magnolia API, or have been looking for Bean2Content or Bean2Node, but an implementation has yet to be seen. So when we want to save object classes to the repository, we are usually stuck creating content nodes, and adding the node data manually. Over and over again.
While working on a new Magnolia tool, the need to persist object structures to the repository arose once again. This time ’round I finally decided that it was time for a simple, yet effective, Magnolia Object Mapping module. Interested??
The Magnolia Object Mapping module (magnolia-om)
The Magnolia Object Mapping module contains a service that uses reflection to access the accessible fields in an object class by their getter-methods. By default the contents of an object is persisted entirely to the Magnolia repository. Any field types that are compatible with Magnolia NodeData, are saved as node data properties of the content node. Any other types and their fields are saved as sub-nodes.
Getting started
Start by downloading and deploying the Magnolia-OM jar in your local library. Add the following dependency to your project:
<dependency> <groupId>nl.trifork.magnolia</groupId> <artifactId>magnolia-om</artifactId> <version>1.0.0</version> </dependency>
Example
Say we have these two very simple objects, An Author and his Books. The getters and setters are removed from the examples for clarity.
public class Author {
private String name;
private String email;
private List<Book> books;
...
}
public class Book {
private long id;
private String title;
private String isbn;
...
}
When saved manually the code will be quite verbose:
Session session = MgnlContext.getJCRSession("config");
Node node = session.getNode("/parent/path");
Node authorNode = node.addNode(author.getName());
authorNode.setProperty("name", author.getName());
authorNode.setProperty("email", author.getEmail());
for (Book book : author.getBooks()){
Node bookNode = authorNode.addNode(book.getTitle());
bookNode.setProperty("id", book.getId());
bookNode.setProperty("isbn", book.getIsbn());
bookNode.setProperty("title", book.getTitle());
}
session.save();
However, after creating some instances and saving this structure using the Magnolia OM service, your code will look like:
mappingService.toNode("/parent/path", "config", myAuthorObject);
This will result in the following Magnolia node structure in the config repository, under /parent/node:
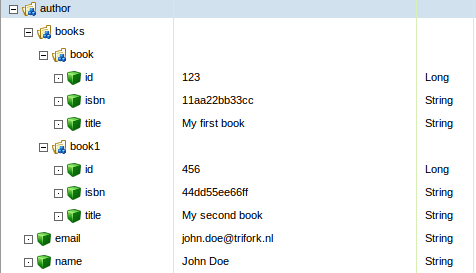
Annotated beans
When you have full control over the contents of your objects, then this straight-forward approach might just be enough for you. However, if you want some more control over what properties are saved, the property names or their types and the Magnolia node types, we have introduced some annotations:
- @MagnoliaNode (name(String), type(NodeType))
Identifies that this type or field should be saved to a sub node.
If the name element is provided, this will be used as the node name. By default the the name of the type or field is used.
With the type element, you can specify the Magnolia node type (Folder, Content, ContentNode). The default type is Content. Please keep in mind that Magnolia content nodes cannot contain folders by design. - @MagnoliaNodeData(name(String), type(int), persist(boolean))
Identifies that the value of this field should be added as node data.
If the name element is provided, this will be used as the node data name. By default the name of the field is used.
The type element defines the javax.jcr.PropertyType to use for this NodeData. For example PropertyType.LONG, PropertyType.DOUBLE, etc. You can use different JCR property types than the field types in your bean. The value is converted for you automatically.
The persist element defines whether this field should be saved to the Magnolia repository or not. The default value is true. - @MagnoliaNodeName
Identifies that the value of this field, or the returned value of a declared method should be used as the current node’s name.
Now let’s adjust the classes a bit, using a couple of these annotations:
@MagnoliaNode(type=NodeType.CONTENTNODE)
public class Author {
@MagnoliaNodeName
private String name;
private String email;
@MagnoliaNode(type=NodeType.CONTENT)
private List<Book> books;
...
@MagnoliaNode(type=NodeType.CONTENTNODE)
public class Book {
@MagnoliaNodeName
@MagnoliaNodeData(persist=false)
private long id;
private String title;
@MagnoliaNodeData(name="isbnNumber",type=PropertyType.STRING)
private String isbn;
...
Behavior
- The Author object will be saved as a Magnolia ContentNode.
- For the Author object, the value of the field name will be used to name the Magnolia ContentNode.
- The value of the field books in Author will be persisted in Magnolia Content.
- The individual Book nodes will be saved as Magnolia ContentNodes.
- The value of the field id in Book will be used to name the individual book nodes.
- The field id in Book itself will not be persisted as node data, it’s just used to name the node.
- And finally in Book the value of the field isbn will be saved to a Magnolia string NodeData property called isbnNumber instead of isbn
So if we would persist the object model again, we would end up with:
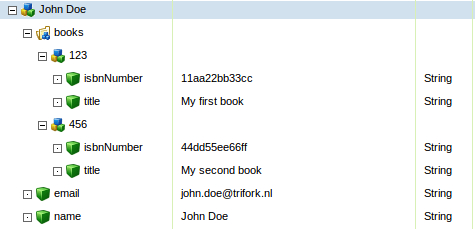
Configuation
As most of our Magnolia modules, this module relies on our Spring context configuration module to initialize the service and expose it to the modules’ class. However, this service can also just be instantiated and called directly.
Spring context
The best way to explain the module structure is by showing you the Spring context. The packages are starting with nl.trifork.magnolia.om, but are abbreviated to om for cosmetic reasons.
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="mappingService"
class="om.service.AnnotationObjectMappingServiceImpl">
<property name="contextProvider">
<bean class="om.provider.LegacyMagnoliaContextProvider" />
OR
<bean class="om.provider.DefaultMagnoliaContextProvider" />
</property>
</bean>
<bean class="om.module.MagnoliaOMModule" factory-method="getInstance">
<property name="mappingService" ref="mappingService" />
</bean>
</beans>
The AnnotationObjectMappingServiceImpl implementation takes a contextProvider as a required property. All of the actual Magnolia API access is abstracted into a Magnolia context provider. The reason for this is that the way to access the Magnolia API differs slightly for either versions before 4.5, and after. If you are using a version before 4.5x, just inject the LegacyMagnoliaContextProvider, and if you are using one of the spanking new Magnolia versions, use the DefaultMagnoliaContextProvider. This way the module is easy to use for any Magnolia version you are using.
No Spring?
If you are not ready to use Trifork’s Spring context configuration module just yet, feel free to instantiate the service as follows:
MagnoliaContextProvider contextProvider = new DefaultMagnoliaContextProvider(); // or use the legacy provider for < 4.5x AnnotationObjectMappingServiceImpl mappingService = new AnnotationObjectMappingServiceImpl(); mappingService.setContextProvider(contextProvider);
You can also set two default behaviors:
mappingService.setDefaultNodeType(NodeType.CONTENT); mappingService.setPersistEmptyValues(true);
setDefaultNodeType (default NodeType.CONTENT)
This sets the default Magnolia node type you want to use. Might be very useful instead of annotating each and every bean to use a different node type than the default one.
setPersistEmptyValues (default true)
This property defines whether to save empty collections, empty maps or null values to the repository. When set to false, these empty node datas and nodes are skipped.
That’s it!
So if you ever need to persist your beans to the repository in the future again, try out this small and easy to use module (Download the JAR!!). I guarantee you that you will not be creating any ContentNodes or NodeDatas manually ever again!!