elasticsearch – how many shards?
We’ve all been there – you’re provisioning for an elasticsearch index and one of the first questions that comes to mind is “how many shards should I create my index with?”. In my previous posts on the subject, I wrote about how to find the maximum shard size for elasticsearch. Although informative, the results of the tests also raised a new question: would more shards on a single elasticsearch node increase performance? In this blog post I’m going to try to show the performance consequences of different choices for the number of shards.
Terminology
If you’re new to elasticsearch, terms like “shard”, “replica”, “index” can become confusing. Experienced users can safely skip to the following section.
Starting from the biggest box in the above schema, we have:
- cluster – composed of one or more nodes, defined by a cluster name.
- node – one elasticsearch instance. Most of the times, each elasticsearch instance will be run on a separate machine.
- elasticsearch index – a collection of documents. An index is composed of one or more shards.
- elasticsearch shard – because elasticsearch is a distributed search engine, an index can reside on one or more nodes. In order to accomplish this, an elasticsearch index is split into chunks, called shards. Shards are automatically managed by elasticsearch, so most users don’t need to worry about the specific implementation details. But, if you’re curious to know, each shard is actually a Lucene index. More information about Apache Lucene (the IR library upon which elasticsearch is based) can be found here.
- primary vs replica shards – elasticsearch will create, by default, 5 primary shards and one replica for each index. That means that each elasticsearch index will be split into 5 chunks and each chunk will have one copy, for high availability. The main difference between a primary and a replica shard is that only the primary shard can accept indexing requests. On the other hand both replica and primary shards can serve querying requests.
Test setup
As with my previous tests, I used my development machine for all tests. Its specifications are:
- i7 3630QM CPU (2.4 GHz)
- 16GB RAM
- Windows 8 64b
- SSD for the OS, HDD for elasticsearch
Elasticsearch was given 6GB of RAM (both -Xms and -Xmx options were set to this value). The rest of the configuration parameters were left at default.
And also as with my previous maximum shard tests, I used the Wikipedia articles dump as document source. For reference, this is how a Wikipedia article looks when indexed in elasticsearch:
</p>
<p>{<br>
id: 88446,<br>
title: "List of Portuguese monarchs",<br>
timestamp: 1372116019000,<br>
contributorName: "Johnmperry",<br>
comment: "typo",<br>
text: "article text",<br>
redirect: false<br>
}</p>
<p>
I tested several number of documents and shard counts combinations, as follows:
- 1 shard
- 2 shards
- 4 shards
- 200.000 documents
- 1 million documents
- 2 million documents
Indexing
The first documents in the dump were chosen so for each shard variant the same documents will be indexed. Indexing was be done with one thread. The results can be seen in the graph below.
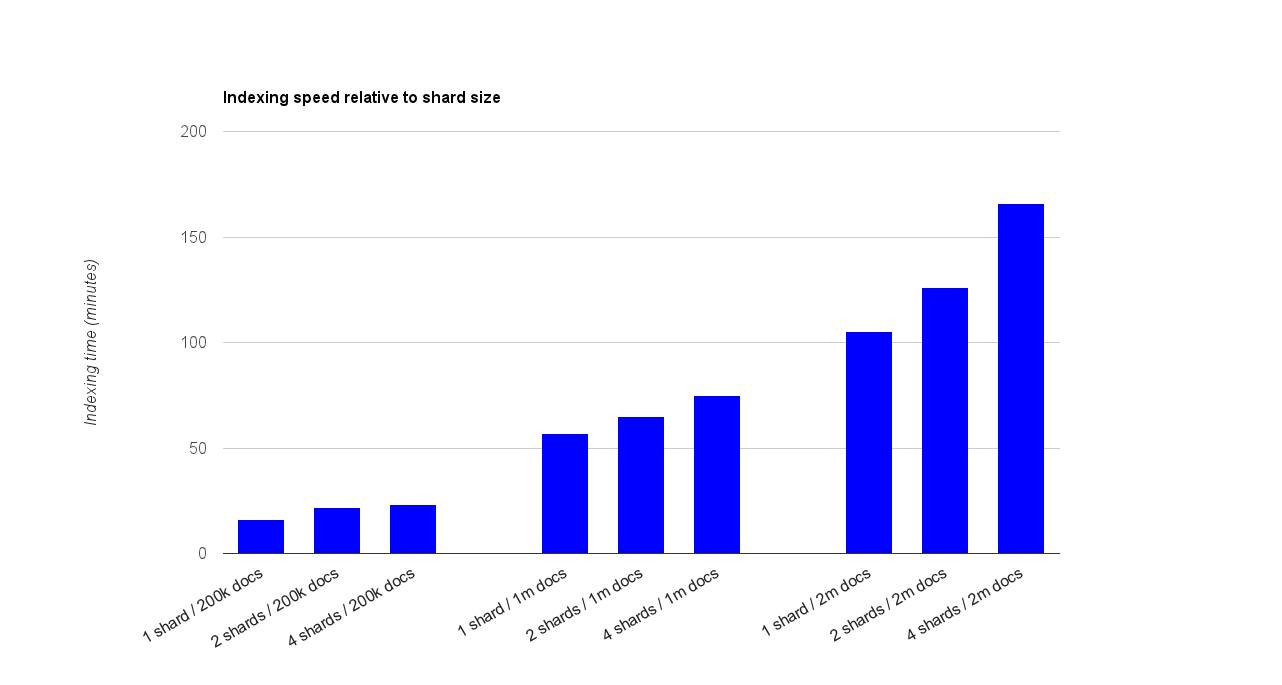
The overhead of creating more shards is noticeable as the number of documents increases. Still, even for 4 shards and 2 million documents, the achieved average performance of 200 documents indexed per second is still acceptable in my book.
Querying
For querying I simulated using JMeter the following variation of concurrent requests:
- 10
- 25
- 50
- 100
- 200
The executed query is given below and it’s worth mentioning that for the sake of result consistency all the elasticsearch indices were warmed-up before executing the measured tests.
<br>
{<br>
"query": {<br>
"filtered": {<br>
"query": {<br>
"match": {<br>
"text": "${SEARCH_STRING}"<br>
}<br>
},<br>
"filter": {<br>
"term": {<br>
"redirect": "false"<br>
}<br>
}<br>
}<br>
},<br>
"facets": {<br>
"user": {<br>
"terms": {<br>
"field": "contributorName",<br>
"size": 25<br>
}<br>
}<br>
}<br>
}<br>
The ${SEARCH_STRING} variable was replaced with a randomly chosen string out of all the cities in the US. The query strings are unique and 10000 requests were executed for each concurrent option. The querying results are shown in the below graph.
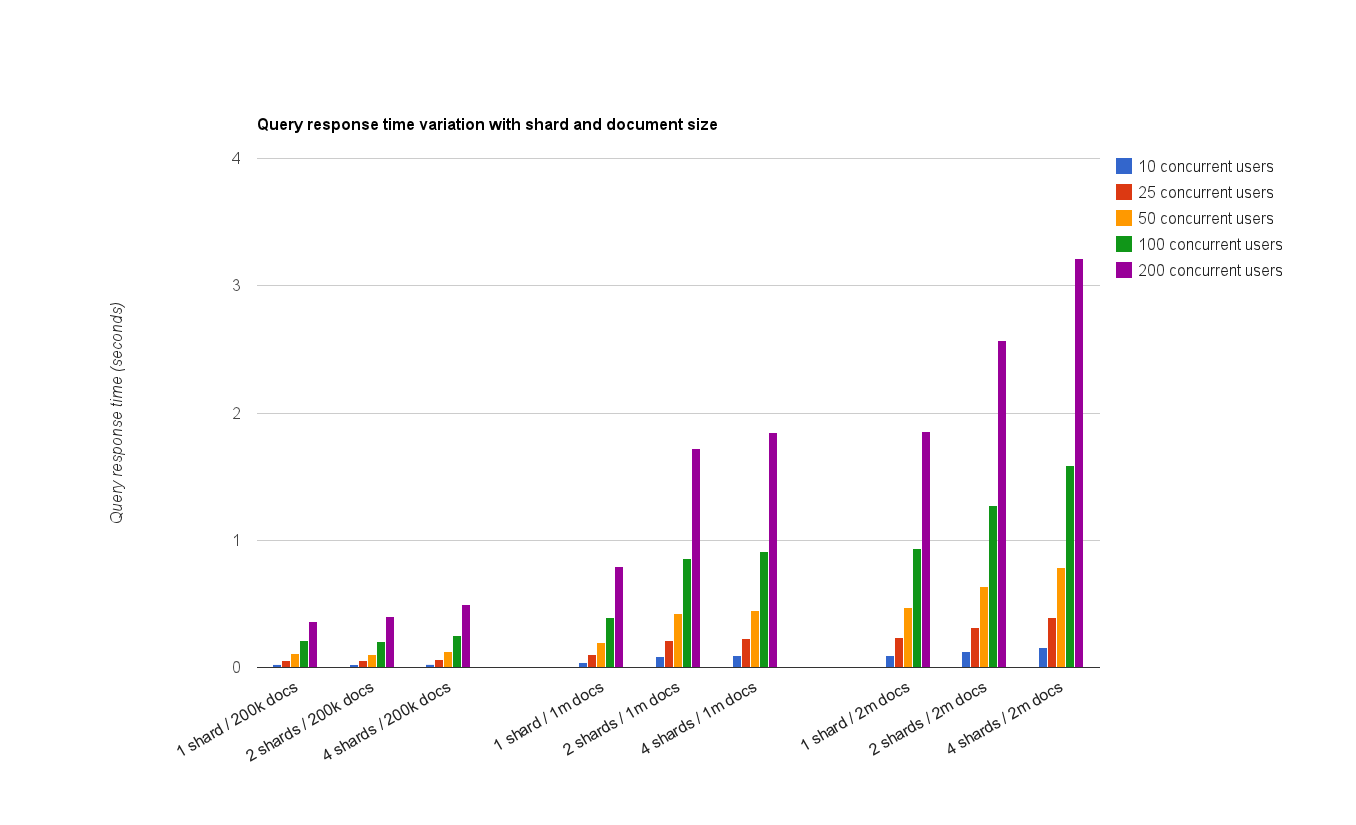
I can’t say I wasn’t surprised with the results. Although I expected a slight drop in response times with more shards, I also expected that for 2 shards, for example, the results would be better than for 1 shard. This was marginally the case for 200.000 documents up to 100 users. For all the other scenarios, having more than one shard resulted in worse performance. Again, as in the case of indexing, differences in results were more significant as the total document count in the index increased.
In conclusion
I believe the main take-away from all this test should be the reminder that shards are not free. They come with a noticeable indexing and a querying overhead, when more than a couple of shards for the same index are created on the same machine. In my test, I was IO limited – for long periods of time, the disk on which the elasticsearch index was created stayed at 100% during both indexing and querying.
Another important aspect to remember is that shards have a natural processing overhead: in order to retrieve a set of results from an index with more than one shard, elasticsearch has to query each shard individually (this is done in parallel) and then execute a reduce step on the aggregated results. Because of this, a machine with more IO headroom (think SSDs) and a multi-core processor can definitely benefit from sharding. The “sweet-spot” recipe for maximum shard size and number of shards per index does not exist unfortunately – tests will have to be made with real world data using real world scenarios.
Lastly, I would like to point out that the conclusion of this post is not “create indices with one shard because that will yield the best results”. Even if that’s what the graphs in this post show, there’s one important aspect to consider: elasticsearch has been designed from the very beginning as a distributed search engine. Creating indices with only one shard will negate that feature, limiting your future growth without a total reindexing of your data.
